
Deep Reinforcement Learning in the Game of Pong
- Nov 13, 2018
- 5 min read
TLDR: Just scroll down to the video and watch reinforcement learning in action.
Reinforcement learning has created quite the stir in recent years. Ever since Deep Mind's AlphaGO defeated the world champion at the game of Go, it has been a phrase on almost everyone's lips (and Google search). Despite it's recent popularity, the concept of reinforcement learning has existed for decades under different names. If one reads the Bellman's book on Dynamic Programming which was published in 1957; we can see the roots of reinforcement learning and visualize it's evolution through time. However, for the purpose of this blog, we will not delve into the mathematics or the origins of reinforcement learning; rather we will try to understand how reinforcement learning works through the classic game of Pong. If you don't know what Pong is, just check out the GIF below and you will figure it out. The goal of the game is to defeat your opponent by hitting the wall behind the opponent's paddle. Every time the opponent misses, you get a point and vice versa.
Now, in this blog I will train an AI to play the pong game against the default AI using reinforcement learning (RL). In it's simplest sense, RL is a trial and error based learning method. For instance, when we as humans try something new, we tend to explore our options in the beginning and see what happens when we choose a particular option. In the case of a game, we tend to push buttons on the keyboard or the controller to figure out what each button does; and with time we tend to get better at the game. In RL the AI (called the agent) explores it's options and there is usually a reward associated with each action.
In the case of pong, there are three actions - go up, go down and do nothing; and the agent receives a positive reward whenever it scores and a negative reward when the opponent scores. And with time, we expect the agent to learn the optimal strategy and become really good at the game. Usually, we use a deep neural network to predict the associated reward with each action and choose the one that maximizes the reward - a concept called Q-learning. I won't go into the specifics right now, maybe I will write another blog post for that.
Why not just see the direction in which the ball is headed and intercept it? Wouldn't that be easier?
While that indeed seems to be the easiest approach (and often the simplest approach is the best), there are a few issues. In this case it seems viable. If the game API allows it, we can just look at the direction in which the ball is headed, it's velocity and just move the paddle to that location. But consider this - is that what we really do when we play a game? Do we actually look at a mathematical value of the ball's velocity and calculate the amount of units we should move up or down to meet the ball. I hope the answer is no. We usually use our intuition to predict the ball's path. And this intuition is what we want the agent to learn. Still, this does not justify why the agent needs intuition; it is a computer, and it can easily do the math. Right?
Well the correct answer is yes, and no. In this case yes, it can easily do the math. However, if we wanted to train the AI on another game, say Breakout, we would need to figure out the dynamics of that game and change our math accordingly. What would happen if it's a more complicated game, say DOTA 2 or Starcraft? In certain other cases it might be impossible to construct the entire state space. Consider an AI playing the game of Go. The game has about 2.08 × 10^170 possible moves. Even the best computers cannot do that many calculations in real-time. In cases like these, RL comes to our rescue. Instead of doing a bunch of math, we just take a sequence of screen shots and feed it to a neural network, and the rest is magic.
Reinforcement Learning in the Game of Pong
Without further ado, let's jump right into my implementation of RL in the game of pong. Remember there are three possible moves (up, down, do nothing) and +1 reward associated with scoring a point and -1 with losing a point. The first one to 20 points wins. Our agent is the one on the left. The default AI is the math based AI that we discussed earlier. Also remember that score and reward are different things. Score is the value displayed on the screen (range 0 to 20). Reward is what trains the AI and the range is (-20 to +20). Stop here for a moment and think why the range is not 0 to 20.
The coding was done in Python 3.6 using the TensorFlow and PyGame packages. I used a sequence of 4 screen shots as one state.
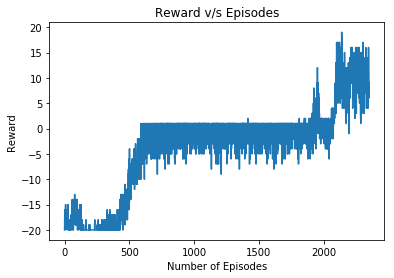
Below is a plot of the total reward per episode v/s number of episodes. Notice how the reward increases with time and reaches a maximum value. In the beginning the rewards stays near the value of -20 but with time it starts to hover around the 0 mark and eventually starts rising towards +20. It should be noted that the plot shown below was another experiment that I conducted with a different random seed. I believe that is why the reward does not quite reach +20. I am guessing about half a million more iterations would have done the trick. Nevertheless, the graph conveys the concept of RL and the increase in reward with time. If I get the chance I will upload the correct graph.
What's next?
At the moment the agent tries to defeat the opponent and becomes really good at it. Too good for practical applications. If I use this agent to play against a human, the human will quickly become frustrated and quit the game. I am trying to modify the reward function to ensure the agent tries to continue the rally with the opponent. Also, I noticed that the agent tends to move a lot, causing a lot of distraction. I will add a small penalty associated with movements to minimize unnecessary actions. I realized that the default AI runs at a predefined speed and as a result the agent has been over-trained at that particular speed. The performance of the agent falls if I increase the default AI's speed. So I am going to train it with a variable speed AI. I still need work out the kinks on that implementation. Hopefully, I will train a couple of other games. But since the process takes a long time to train on my PC (2-4 days), I need to explore cloud computing platforms before proceeding. So stay tuned for more videos and blogs.
Thanks for reading... :)
Comments